本文最后更新于:2021年6月15日 晚上
自从使用 ElasticSearch 重构了主站的搜索项目之后,之后又陆续接入了其他两个项目,目前使用 SpringBoot 方式跑了一个伪集群,主站使用的时候,比较稳定,没有人反馈说有问题。
但新接入的一个站点商务反馈说,搜索不够准确,完全匹配的关键词不是排在搜索结果列表首位,跑到搜索上去看了一眼,确实完全匹配的结果分数不是最高的,导致没有排在结果首位,今天就来解决这个问题。
默认匹配查询
先看看我之前写的查询代码片段,
| MultiMatchQueryBuilder matchQuery = QueryBuilders.multiMatchQuery(query.getQueryString(), "name", "author");
boolQuery.must(matchQuery);
|
这种写法,完全没有对搜索结果的平分进行干扰,只是按照 ES 的默认分词计算匹配度的结果。
权重查询
我尝试了使用权重查询,即提升某些字段的权重,但是设置之后,结果反而更加不尽如人意。
| boolQuery.should(QueryBuilders.matchQuery("name", queryString).boost(3.0f));
boolQuery.should(QueryBuilders.matchQuery("author", queryString).boost(1.f));
|
这样进行查询之后,如果想要查询作者,但是作品名称的权重更高些,所以完全匹配的作者也被排在了后面。
最佳字段查询
看了官方博客和一篇博客文章,发现 multi-match-query 的高级查询方式。
multi_match 多匹配查询的类型有多种,其中的三种恰巧与 了解我们的数据 中介绍的三个场景对应,即: best_fields 、 most_fields 和 cross_fields (最佳字段、多数字段、跨字段)。
这里我们想要搜索时,完全匹配的关键字排名更靠前,所以这里使用最佳字段 best_fields 进行查询
| MultiMatchQueryBuilder multiMatchQuery = QueryBuilders
.multiMatchQuery(queryString, "name", "author")
.type(MultiMatchQueryBuilder.Type.BEST_FIELDS)
.tieBreaker(0.1f);
boolQuery.must(multiMatchQuery);
|
首先设置 type 为 BEST_FIELDS,其次,我们想要完全匹配的分数高点,那么就让没有完全匹配的分文档评分低即可,我这里乘以了 0.1 的系数,系数的范围是 0-1 之间。
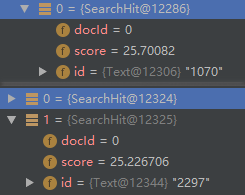
加上了系数之后,不完全匹配的文档评分就被拉开了,就达到了我的最终目的。
最佳字段优化
2019年01月19日08:01:31 更新
通过上一步优化,已经提升了完全匹配文档的评分,但是还不足以拉开评分
现在是作品名称/作者两个字段都存在相同的值,但是想让作品名称字段的权重更高点,即搜索相同值的时候,优先搜索出作品名为该值的数据
最终优化结果:
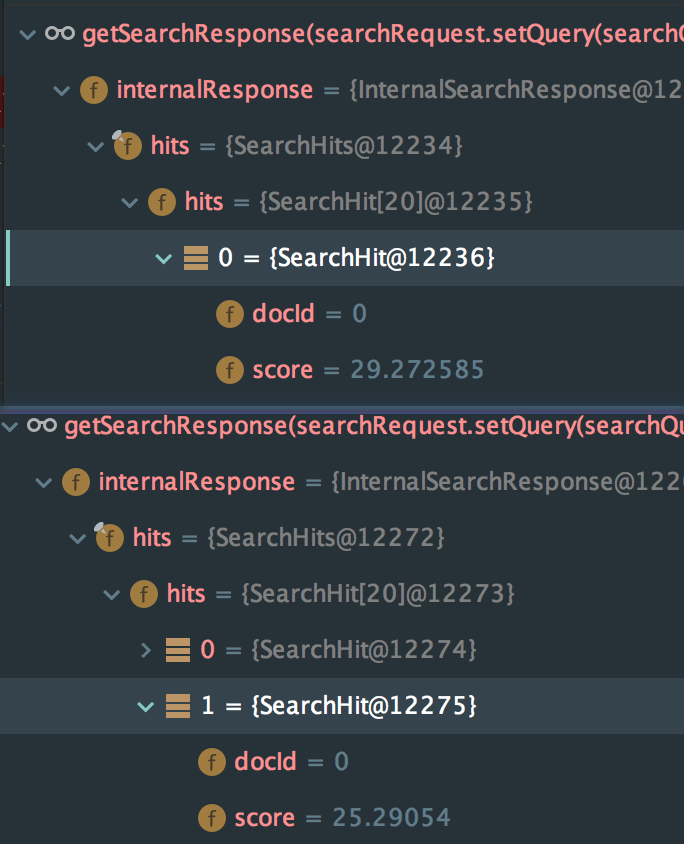
代码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| public void testHighlightQuery() {
BookQuery query = new BookQuery();
query.setQueryString("穿越");
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
PageRequest pageRequest = PageRequest.of(query.getPage() - 1, query.getSize());
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder()
.withQuery(boolQuery)
.withHighlightFields(
new HighlightBuilder.Field("name").preTags("<span style=\"color:red\">").postTags("</span>"),
new HighlightBuilder.Field("author").preTags("<span style=\"color:red\">").postTags("</span>"))
.withPageable(pageRequest);
String queryString = query.getQueryString();
MatchQueryBuilder nameQuery = QueryBuilders.matchQuery("name", queryString);
MatchQueryBuilder authorQuery = QueryBuilders.matchQuery("author", queryString).boost(0.8f);
DisMaxQueryBuilder disMaxQueryBuilder = QueryBuilders.disMaxQuery().add(nameQuery).add(authorQuery);
queryBuilder.withQuery(disMaxQueryBuilder);
NativeSearchQuery searchQuery = queryBuilder.build();
Page<Book> books = elasticsearchTemplate.queryForPage(searchQuery, Book.class, extResultMapper);
books.forEach(e -> log.info("{}", e));
}
|
主要通过 QueryBuilders.disMaxQuery 结合 boost 对非核心字段降低权重来完成
资源下载
参考