WebMagic实现分布式抓取以及断点抓取
本文最后更新于:2021年6月15日 晚上
前言
从去年到今年,笔者主要负责的是与合作方的内容对接,新增的合作商不是很多的情况下,在我自从去年引入了 WebMagic 这个爬虫框架之后,基本很少需要去关注维护爬虫,做的最多的是新接入合作商去写对应爬虫抓取模板。
因为在代码中实现了增量抓取,单机也足以承担日常的抓取工作。
在前两周,由于公司拓展新的业务渠道,需要接入的合作商瞬间增加了 3 倍,又被要求在 2 天内全部接入,那两天和另外一个同事,几乎都在忙着适配模板。
急速增加合作商的同时,服务器无法承受压力,频繁爆出 OOM 异常,导致抓取大批量失败,其中最多的一个合作商接口,需要解析下载的页面近 500w 个,单机抓取已无法满足需求,需要多台服务器同时抓取。
但鉴于当时需求紧,没有时间对爬虫部分代码进行重构升级,单机抓取也不行,而且会影响正常抓取任务的执行,于是临时想了个办法在其他服务器上抓取某个合作商,才坎坷解决了这个问题,但这也并非长久之计。
分布式抓取基础前提之一
因为刚刚引入 WebMagic 这个框架的时候,还不是太熟悉,使用的 Scheduler 是默认基于内存的队列 QueueScheduler ,当待抓取的 URL 太多时,内存就被占满了,从而导致 OOM。
如果要实现分布式抓取,前提需要使用基于 Redis 的 RedisScheduler。
在创建爬虫的时候,手动设置 Scheduler 为 RedisScheduler。
1 | |
RedisScheduler 需要传入 JedisPool 参数。
如果使用的是 SpringBoot,可以声明一个 RedisConfig 的配置类。
1 | |
如果使用的是 Spring,可以在 XML 中配置声明一个 Bean 节点。
1 | |
声明了 JedisPool 之后,直接在代码中注入即可。
1 | |
分布式抓取基础前提之二
仅仅配置了 RedisScheduler,还无法达成我们的进行分布式抓取的目的,如果需要进行分布式抓取,其队列应该是共享的,即多台服务器的多个爬虫使用同一个 Redis URL 队列,取 URL 或者添加 URL 都是同一个。
又因为是 WebMagic 在帮助我们管理 Scheduler,所以 URL 的维护也是 WebMagic 在做。
先看一段 WebMagic 的源码
1 | |
可以看到 WebMagic 抓取的时候通过这行代码获取队列中待抓取的 URL 地址。
1 | |
而这个 this 是指实现了 Task 接口的对象,即把当前的 Spider 对象作为参数传入。
因为我们使用了 RedisScheduler,所以进入该类的 poll() 方法查看。
1 | |
通过 task 的 UUID 获取到队列的 key,然后利用 redis 的 list 的 lpop 命令从队列左侧弹出一个带抓取的 URL,构造 Request 对象。
同样的查看 poll 上面的 pushWhenNoDuplicate 方法,是将待抓取请求的 URL push到队列的右侧,而这个队列也是通过 Spider 的 UUID 里唯一确定的。
1 | |
所以,如果要实现分布式同时抓取同一个队列,就需要保持 多个 Spider 的 UUID 是一致的
实现分布式抓取
用过 WebMagic 的人都知道,爬虫启动需要给他一个起始 URL,然后通过这个 URL 获取新的 URL;所以如果需要进行分布式抓取,肯定爬虫的起始 URL 是不能相同的,因为WebMagic 会对重复的 URL 进行自动去重。
因此爬虫的架构图从
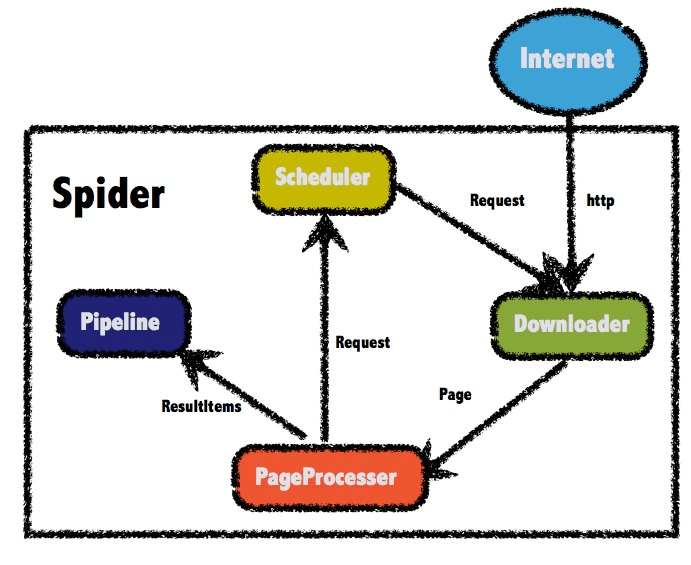
变成了如下架构
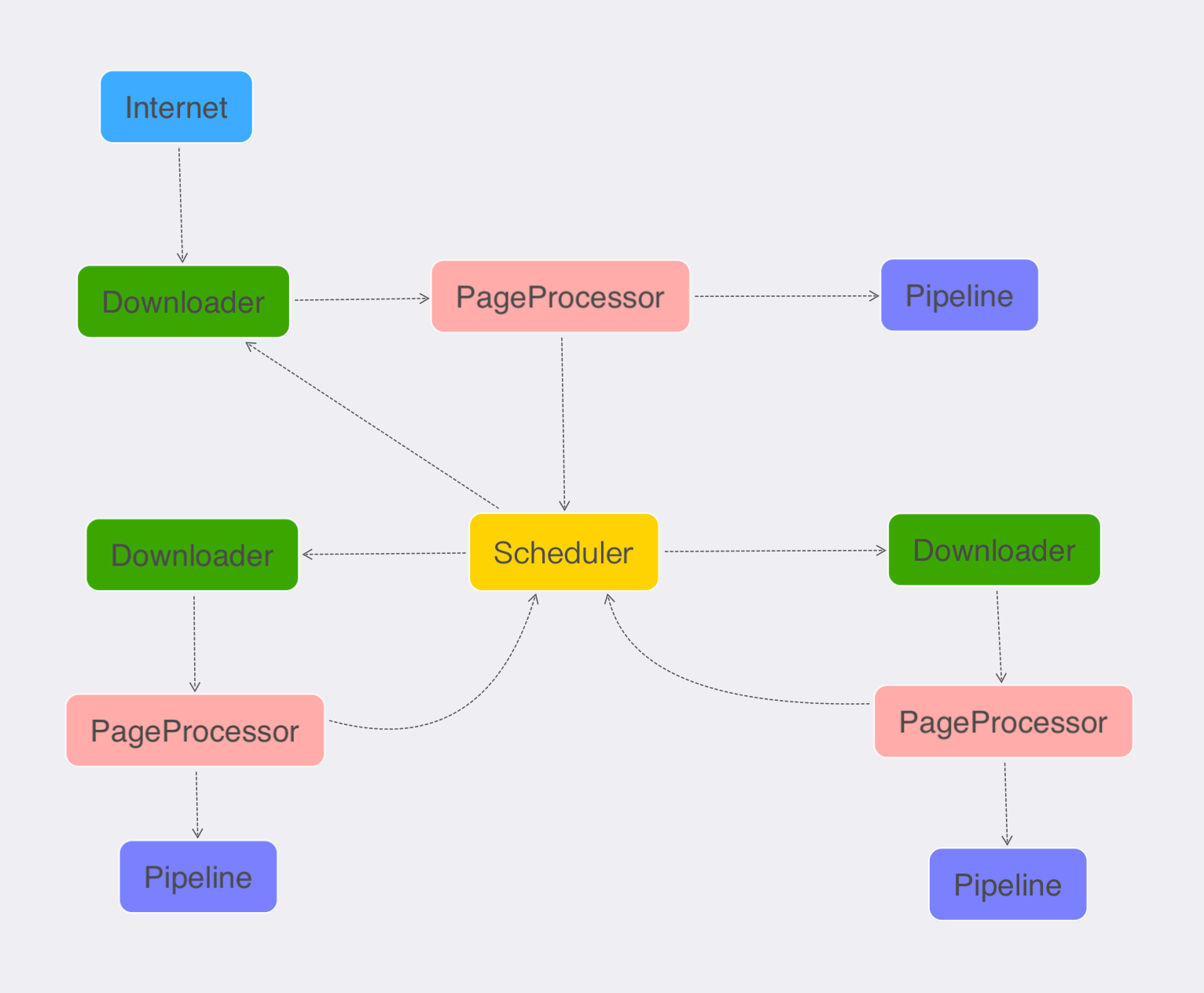
即保证多个爬虫使用同一个 Redis 队列。具体思路就是第一只通过起始 URL 爬虫启动的时候,记录启动爬虫的设置UUID,然后启动其他爬虫的时候,设置爬虫的 UUID 为记录的 UUID 的值。
代码中体现的就是如下所示:
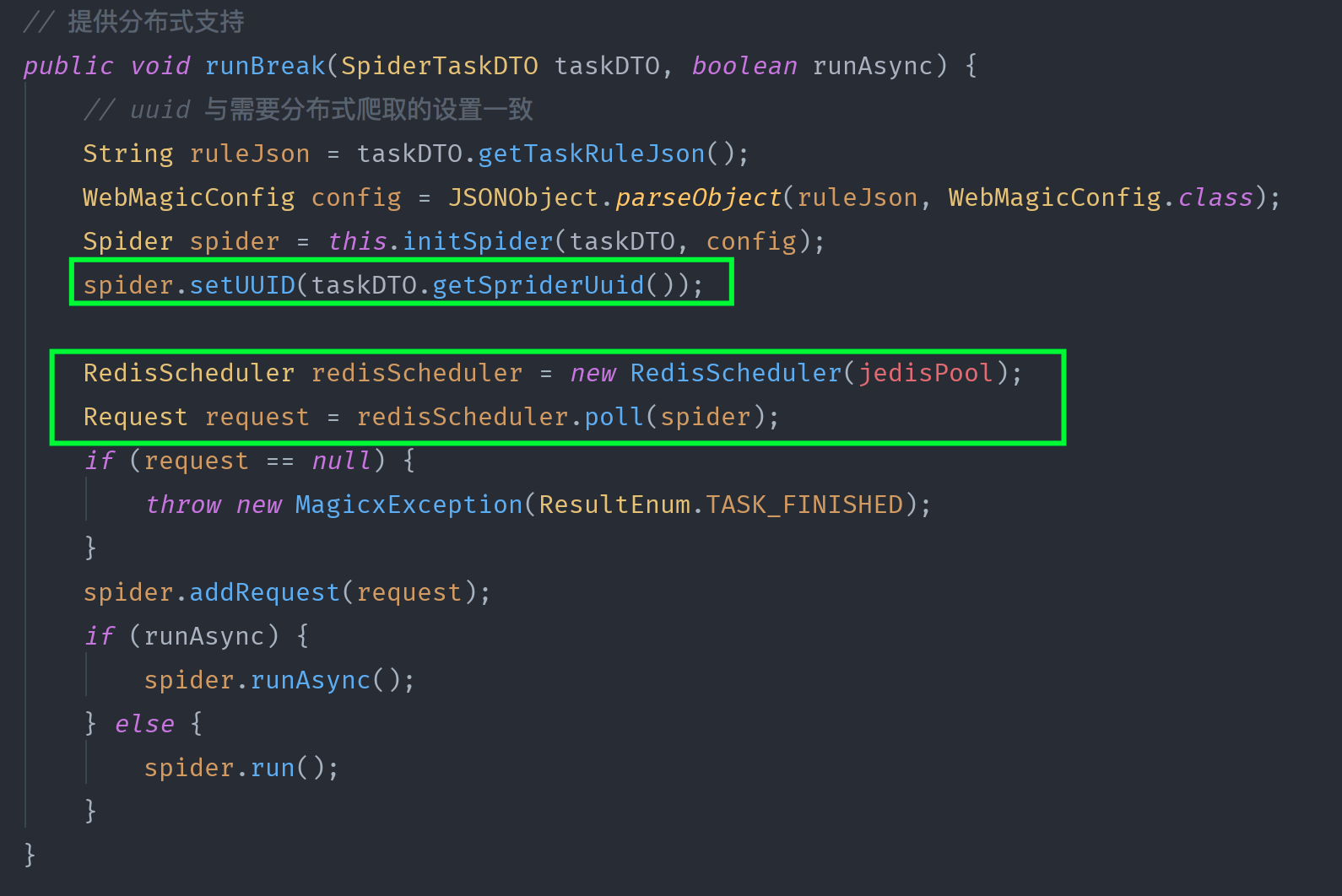
启动其他爬虫的时候,手动从队列中获取 URL 设置为启动 URL 即可。
分布式爬虫任务调度
笔者实现的爬虫启动是通过定时任务启动的,因为其他爬虫与第一只爬虫的入口不同,因此定义了两个任务去调度,并且两个任务之间有 30s 的间隔时间,防止第一只爬虫还未添加 URL 到队列当中,而造成其他爬虫无 URL 可抓取情况的发生。
基于这个思路,因 URL 放在 Redis 之中,所以同时也可以实现 断点抓取。
结语
WebMagic 的源码很简洁易懂,可以学习到很多东西,尤其是多线程以及锁的应用,很值得借鉴学习。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!