WebMagic源码阅读之Spider
本文最后更新于:2021年6月15日 晚上
总是觉得自己平时总是在写逻辑代码,于是学习设计模式,但是又觉得无处可施展,对于如何提高自己的编码能力总是困惑,也曾看了一些源码,但总因为难度太大而不了了之。因为大多数的开源框架源码随着版本的更迭,难度越发上升源码愈发晦涩难懂,但源码还是不能不读,所以觉得从最简单的源码开始读起吧,因为工作中,用到了 WebMagic 框架,于是决定从它开始,为了降低阅读难度,我选择了第一个 tag 版本的源码开始阅读,从易入难,由浅入深,希望自己 2019 年代码能力能有所提升!
下载源码
首先在 IDEA 上把 WebMagic 的源码 clone 到本地
然后 checkout 第一个版本的 tag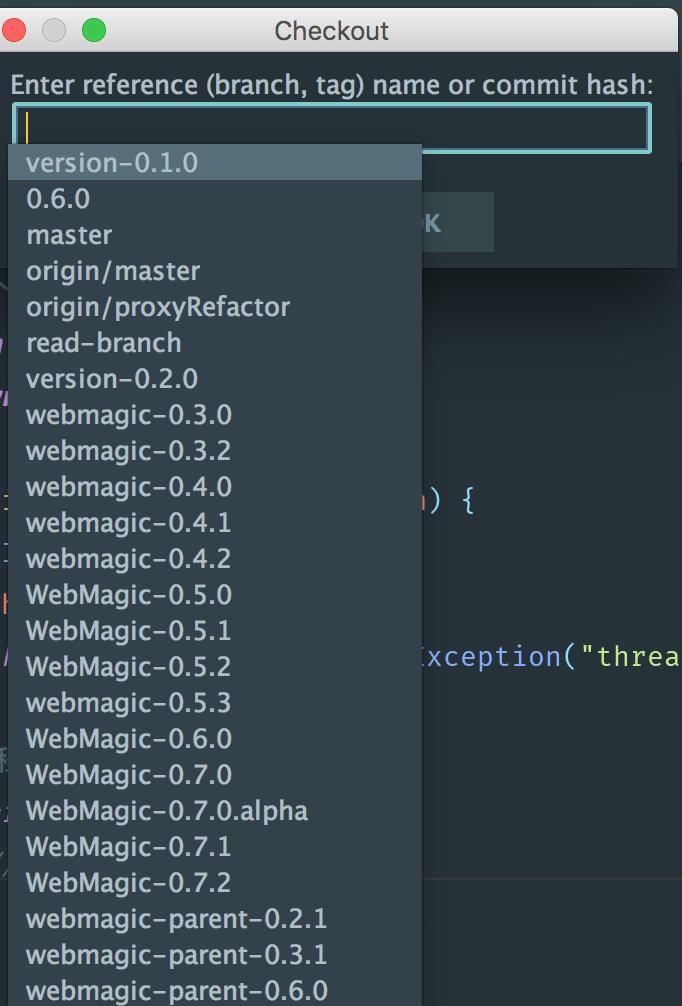
在对话框中,使用智能提示快捷键展示出所有的 tag,默认快捷键是 ctrl(command) + 空格,因为可能会和输入法冲突,我修改成了 command + ;
我选择了 version-0.1.0 版本,然后基于这个 tag,创建了自己的本地分支,便于在上面进行添加注释等操作。
阅读 Spider 源码
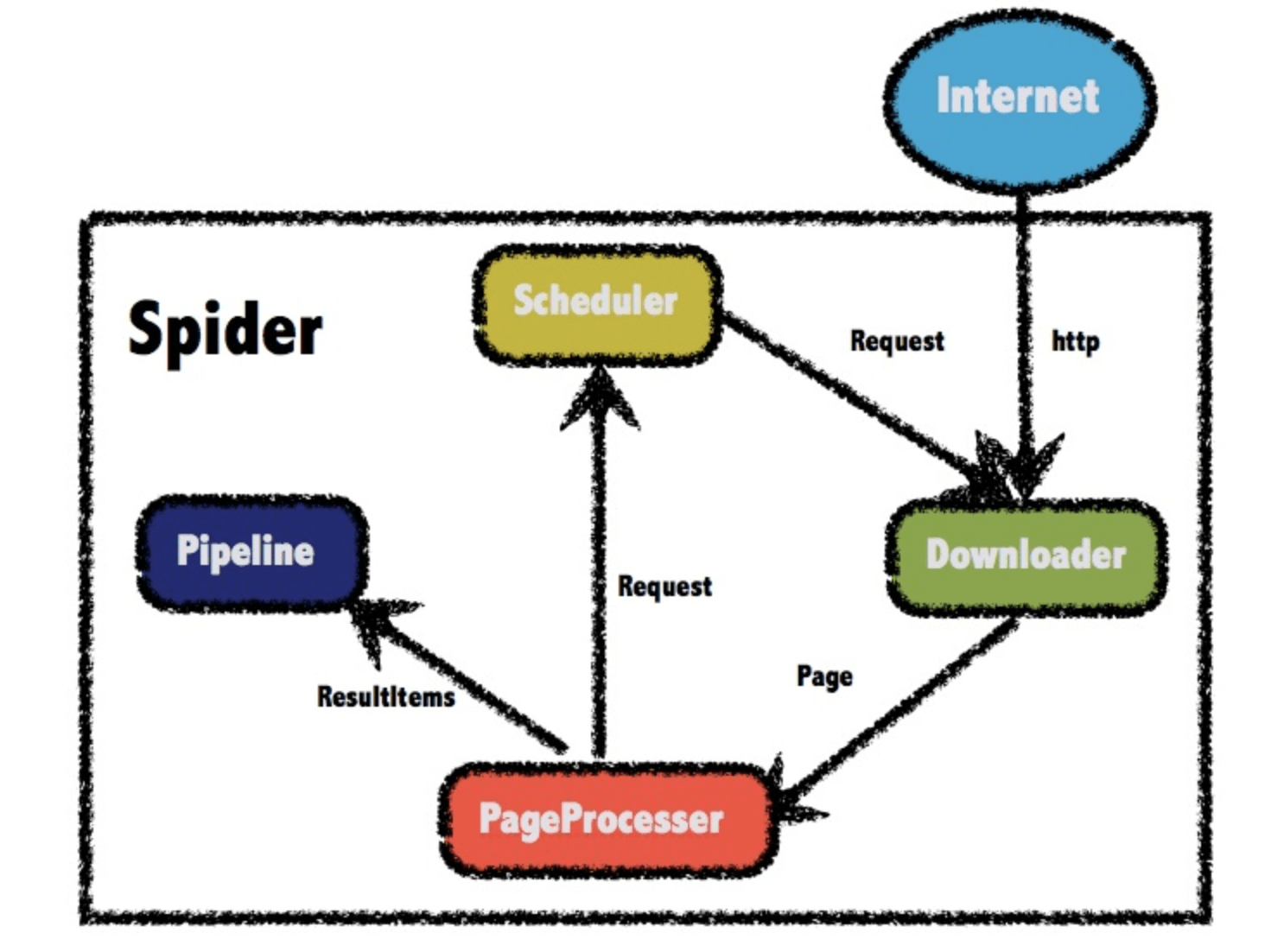
参见官网架构图,Spider 这个组件是 WebMagic 框架的核心所在,同时也是爬虫的入口类,Spider 将各大组件串联起来,共同工作。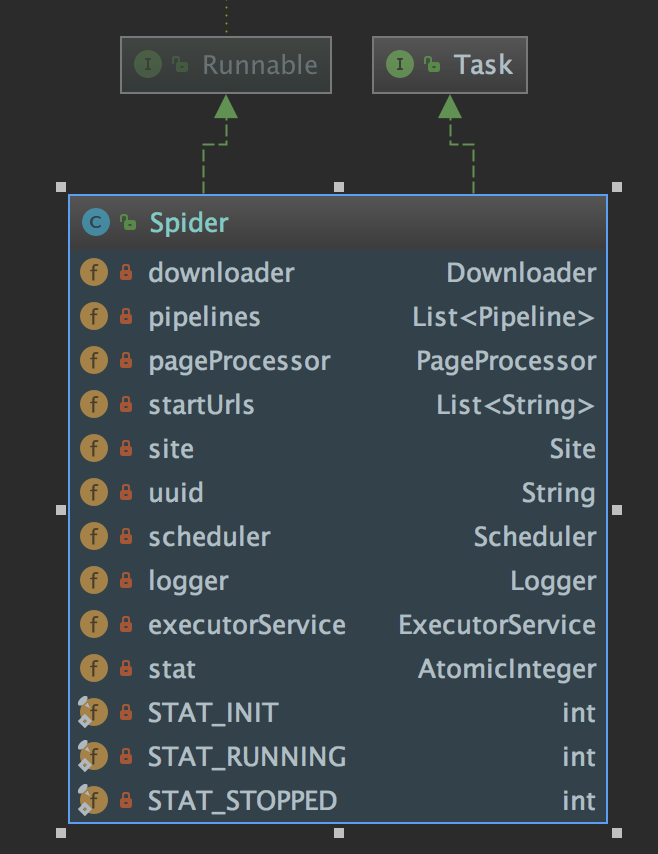
Spider 实现了 Task 和 Runnable 接口,Task 提供了两个接口方法,一个是 getSite(),另外一个是 getUUID(),爬虫运行时,将爬虫自身引用传递到各个组件进行处理。
一般使用 WebMagic 时,通过 Spider.create() 方法创建爬虫,创建时可以指定 Downloader、Scheduler、PageProcessor、Pipeline 这几个组件,作者将这四个组件抽象成了接口,方便扩展,其中 PageProcessor 是必须指定的组件,其他的组件 WebMagic 提供了对应的默认值。
Spider 类主要核心是 run 方法
1 | |
总结
从源码中看到,对于多线程共享资源活跃线程数的处理,使用到了 Integer 的原子类 AtomicInteger,保证活跃线程数量在多线程情况下统计结果的正确性。
作者将四大组件抽象成了接口,面向接口编程,方便扩展,很值得学习。
因为是初始版本,不可避免的会有一些明显的 Bug 存在,比如在 page 类的 addTargetRequests 方法中应该用 continue,但是错用了 break的情况,所以初始版本源码阅读完成后,需要读读新一些版本的源码。
联系
独行的路总是孤独的,希望能找到一些小伙伴共同进步哈哈~
QQ 群号:967808880
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!