爬虫元素选择技巧
本文最后更新于:2021年6月15日 晚上
前言
作为一个爬虫框架,WebMagic 提供了多种选择器便于我们的使用。使用 Selectable 来对内容进行链式抽取,常用的抽取方式有:CSS 选择器、XPath,正则表达式,JsonPath。今天写写如何利用一些工具,来快捷编写这些选择语法。
工具
工欲善其事必先利其器,有了一件趁手的兵器,干起活来也利索。工具主要用到了
- Chrome 谷歌浏览器
- Chrome 插件 XPath Helper
(如果你翻不了 Q 的话,可以在这里 下载 插件)
选择对象
为了方便实验,我选择对 掘金 (https://juejin.im/) 这个网站进行实验。
以下内容默认使用的是 Chrome。
定义一个假的需求吧,需要对掘金热门进行爬取,如下所示。
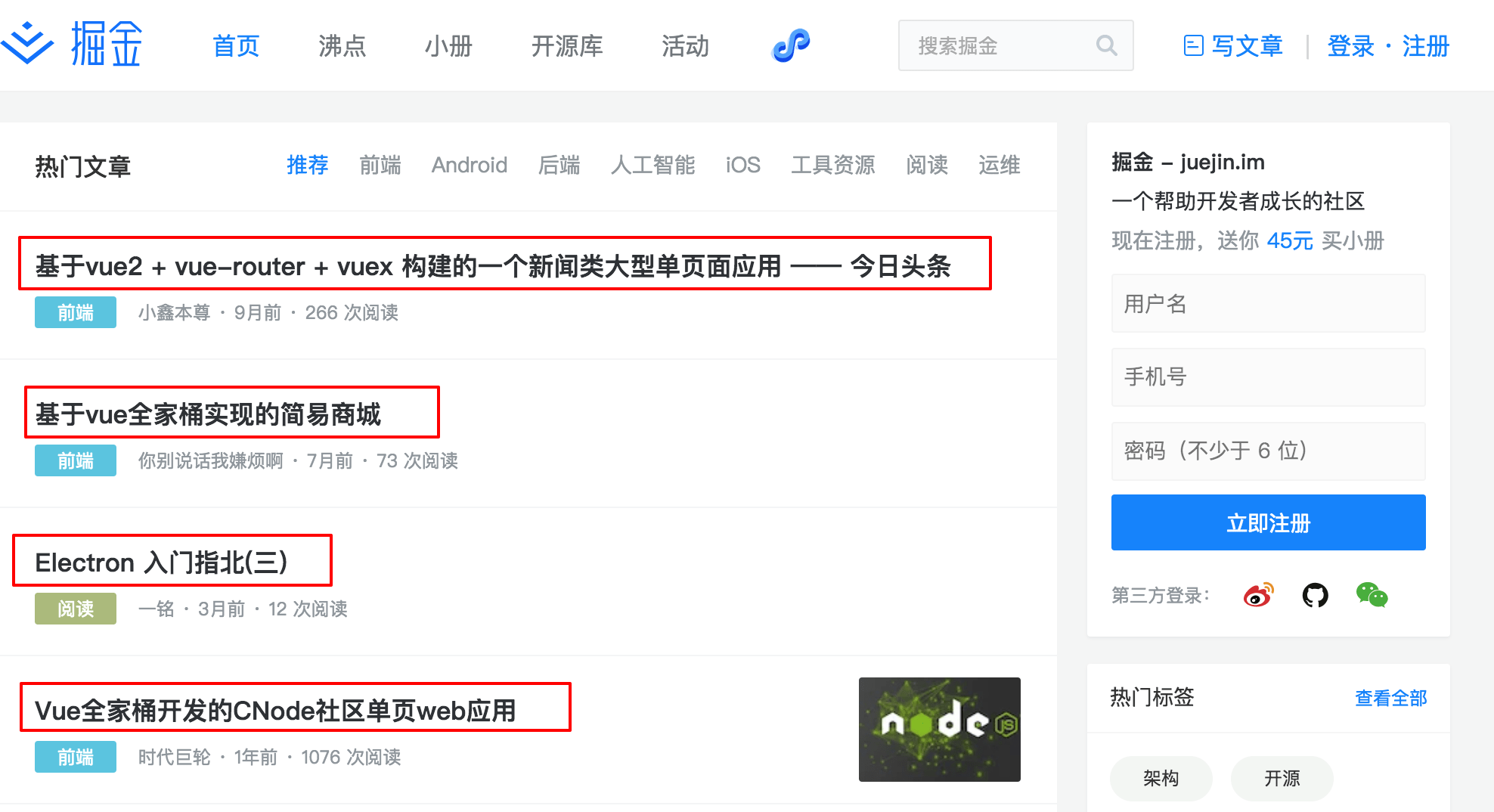
这里我们只想要获取这里的所有的标题
Xpath 抽取
具体步骤:
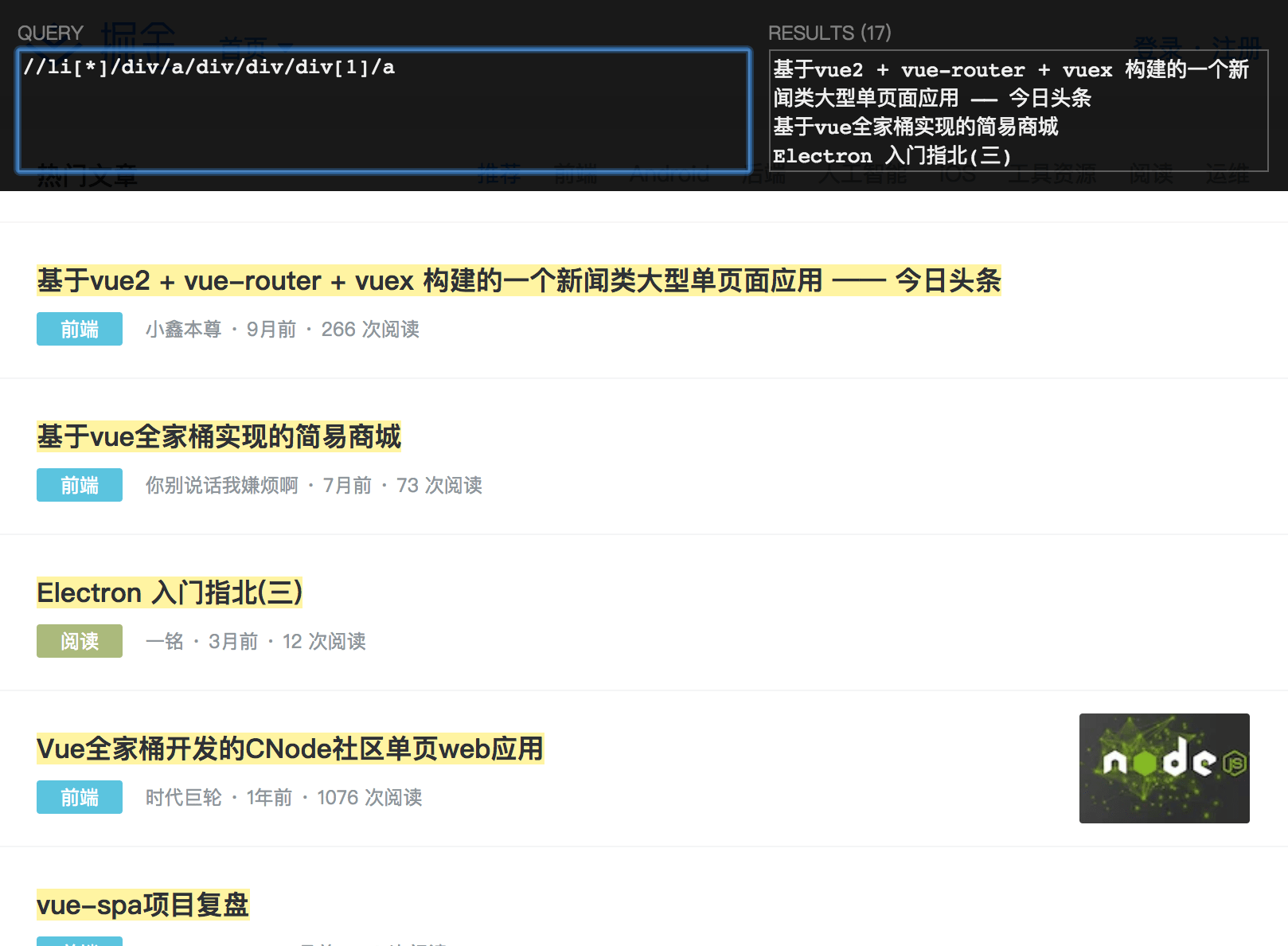
- 点击页面空白处,使用快捷键 ctrl + shift + x 调出 Xpath Helper 工具,调出后,按住 shift 移动鼠标可以选择元素,并且该元素的 xpath 会显示在上方框内
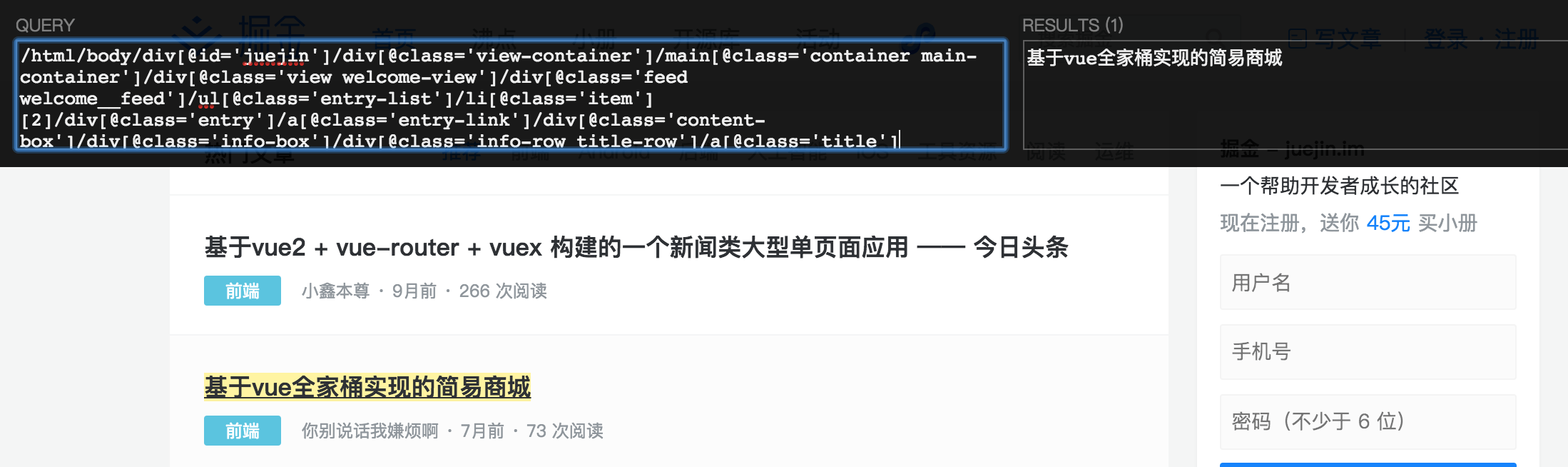
- 可以看到,工具生成的 XPath 路径非常长,需要进行优化。这里可以使用谷歌浏览器的开发者工具很方便得获取 Xpath 路径,打开开发者工具,使用开发者工具面板上最左侧的箭头选择工具,选择一个标题元素,右侧就会自动定位到该元素的源码处,右键源码里的这个元素,选择 Copy XPath。
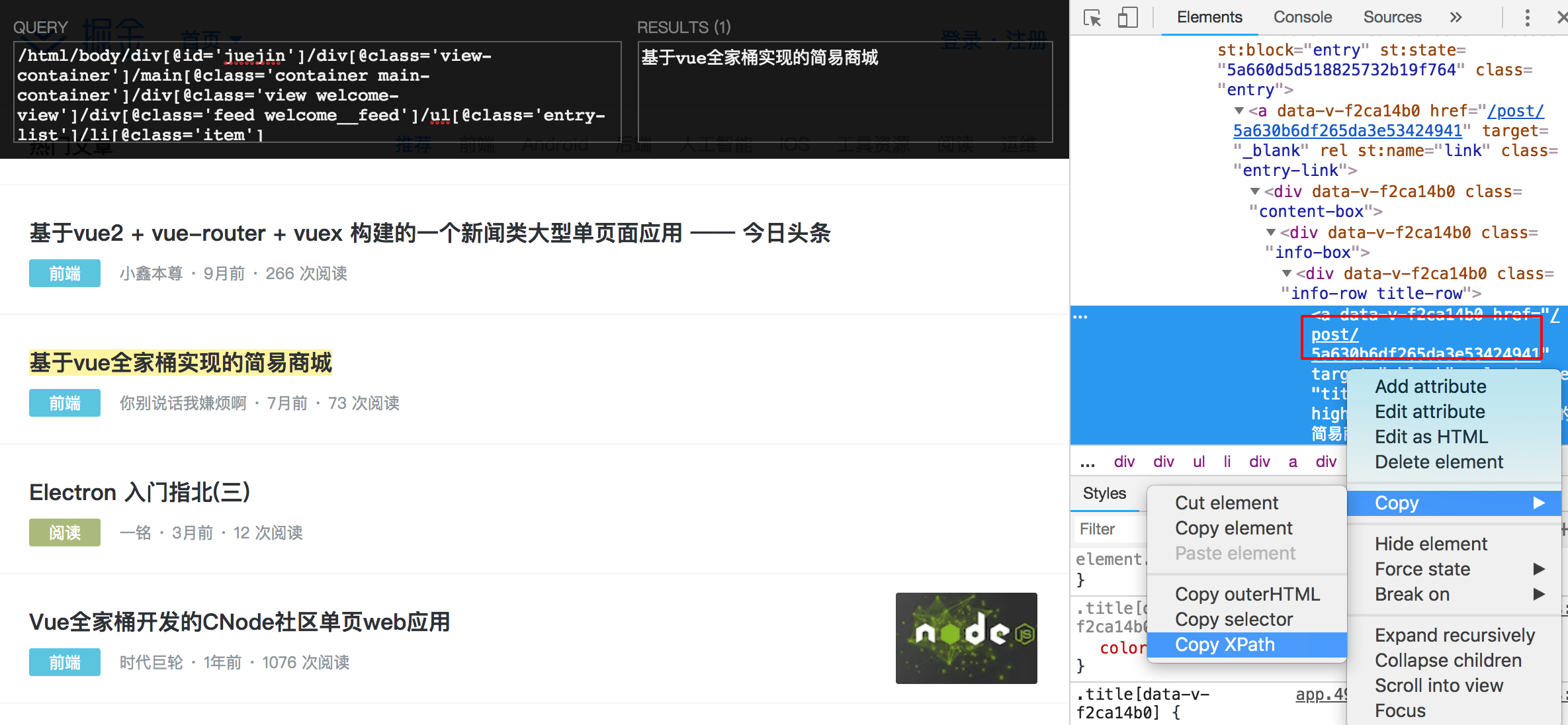
- 清空 Xpath Helper 中的 QUERY 框内的内容,粘贴 Chrome 开发者工具拷贝的 Xpath 路径,可以清晰对比看到路径相纸上一步获取的要简短很多,我们可以在这个基础上进行进一步地优化。
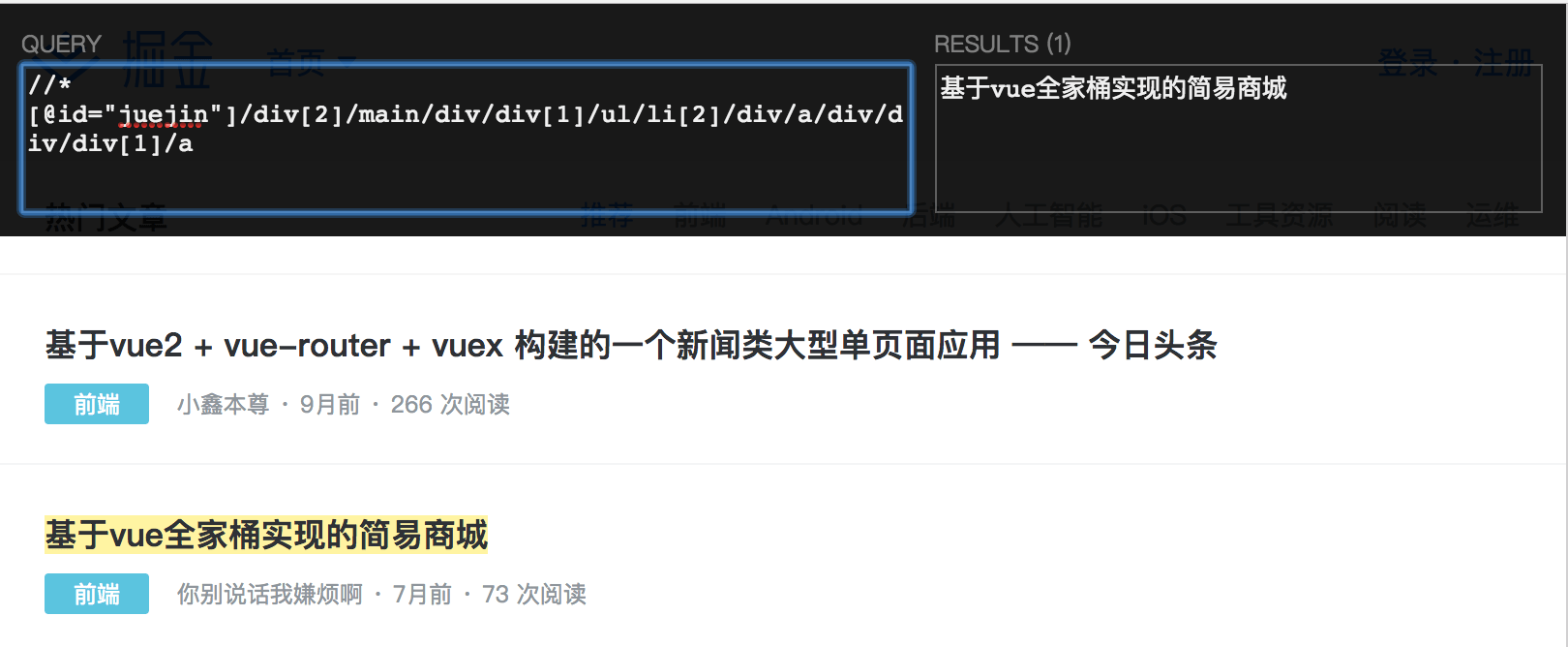
- 由于我们需要获取的是所有的标题,所以修改 Xpath,同时 Xpath Helper 高亮了被选择的元素。因为当前标题是在一个列表页当中,把 li[2] 中的值修改为 * 就是选择所有了,// 表示从根元素查找,替代掉了前面多余的元素, XPath 基础语法可以上 Google 搜索一下。
CSS 选择器
有的网站的 HTML 结构不适合使用 XPath 来写,会写的很长,可以尝试使用 css 选择器来完成,这里还是借助 Chrome 的开发者工具。
- 同上一步一样,选择一个元素后,选择 Copy selector
- 可以在 Chrome 开发者工具的 console 里验证选择器是否正确,这里正确打印出了这个元素。在 webmagic 里通过 css 方法或者 $ 方法传递 css 选择器参数,得到对象.

json path 方式
详见我的另外一篇博客
正则表达式方式
这个就不用多说了,通过正则抽取正文符合的内容
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!